Greg Cordover
Thoughts & projects
Btrfs
Retrieving data from a storage device is fairly simple, assuming an you know which track and sector the data is stored in.
However, it is simply impossible for a person to remember all of these positions. A modern hard drive can store 8x10¹² individual bits of data!
An Intro To Filesystems
To solve the issue of remembering where files are on a disk, we have filesystems. One of the original filesystem is named FAT, or File Allocation Table. Although it was designed originally for floppy disks, it was used from DOS to Windows ME, and still lives on today.
A filesystem is just a fancy term for a big catalog of where files are. It stores the location of the beginning and end of files on the drive. Now we can look up this data, we can easily open any file.
FAT is just one of many filesystems that exist. As a result of the lacking ability of computers at FAT’s conception, it had to efficiently do the minimum to work correctly, and it did this well.
Modern computers have significantly quicker disk write speeds, vastly larger quantities of RAM, and incredibly fast CPUs. With these, we introduced journaling filesystems.
Journaling Filesystems
If you were to unplug a computer using a FAT filesystem while it was writing or moving files, it would be left in an inconsistent state: the files might have moved and the catalog may or may not have been updated. These situations often lead to dataloss, as the system does not have an effective method of handling it.
NTFS, the filesystem in use by Windows today, is a journaled filesystem. The ext4 filesystem used by a great number of Linux installations is a journaled filesystem. Mac OS X uses HFSJ, again a journaled filesystem.
By journaling, or saving a log, of all of the changes being made, a system can replay events to determine the current drive state and what still needs to be done. If data was left in an unknown state, it can scan just a small area and determine what still needs to be done.
However, journaling filesystems are not perfect at preventing data loss. They are much better than filesystems that are not journaled and they do recover from sudden failures faster.
Journaling does absolutely nothing in the case of sudden storage failure. In the event that a hard drive or flash drive completely stops working, there is little that can be done to recover the data.
RAID
As data storage becomes less expensive, we can introduce tools such as RAID, a redundant array of independent disks. By storing at least two copies of all your data and filesystem information over two or more drives, a sudden drive failure will be less of a disaster. Even though one drive is no longer operational, the second drive contains all of your data. While this does not replace backups, it makes recovering a much faster operation.
There are different levels of RAID, or how the data is distributed across the varying number of drives. RAID0 is the least safe type of RAID, because there is no data redundancy. Its advantage is the ability to store single files larger than any single drive you have. RAID1 has a single parity drive, or a drive where an entire backup is stored. RAID6 allows for two drives to fail in a group of four without any data loss. There are a few other types, but they are not commonly used or combinations of the above.
RAID undoubtedly does have its own issues. If data becomes corrupted on one drive, it may try and replace the good data with this bad data. Hardware RAID controllers may fail and leave data nearly impossible to recover. You may have to bring the RAID system offline in order to perform data recovery.
As computers continue to evolve, new technologies are invented that can utilize new features to solve previous problems.
Btrfs
Btrfs is a relatively new filesystem that was designed to fix many of these issues. Btrfs can be used in a fashion similar to RAID with multiple drives, or it may be used on a single drive. Unlike RAID, it not just stores the file, it also stores a checksum of what the file should be.
Data Integrity
A checksum is a function performed on a set of data that returns a mostly unique and repeatable representation of this file or information. Changing even a single bit of data will yield an entirely different result. They are used frequently throughout programs in order to verify that there has not been data corruption or that the data has not been tampered with.
Here’s an example of what checksumming data looks like, you may enter some text to see a CRC32 checksum of it.
Enter textWith 4 billion possible combinations, the output is nearly always a different, unpredictable result, and the same input will always return the same output.
Now that this checksum is stored, a computer can determine when a file has changed from what it should have been. Assuming that your data is in at least RAID1, it can restore the file that matches the checksum, instead of having uncertainty of which file is correct.
Advantages over RAID
Btrfs also allows far more flexibility than RAID. When using a RAID1 configuration, you have to have identically sized disks so that the data may fill up the entire drive. I don’t always have even numbers of same capacity drives, and having to sacrifice disk space for data safety is not economical or practical. With Btrfs, I can create something similar to a RAID1 array with at least two drives, but can have any number of differently sized drives.
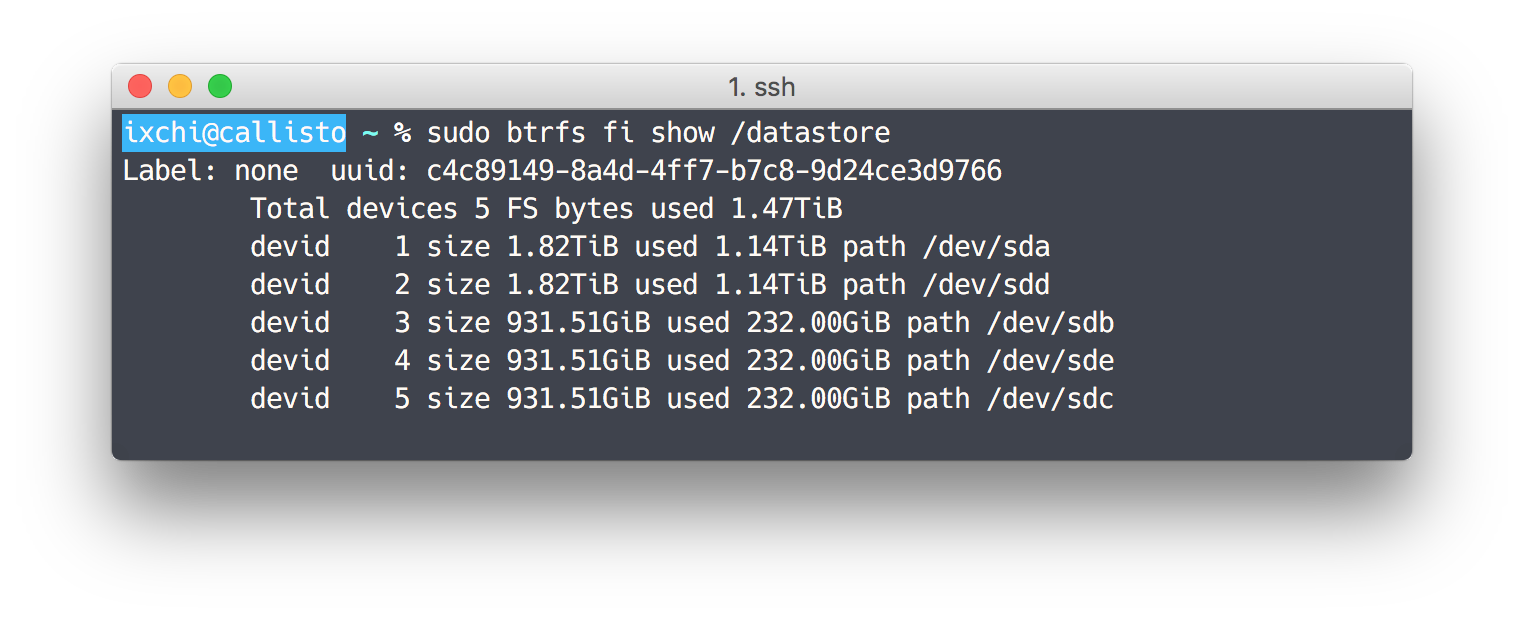
My current Btrfs array has 5 different drives in it, two 2TB drives and three 1TB drives. It intelligently places all data and metadata on two drives. If any drive were to fail, I would simply buy a replacement drive and tell Btrfs to replace the previous drive with this new one.
Btrfs offers transparent compression, meaning that any data saved on a drive is compressed when saving and decompressed when reading. While this requires using more CPU, it can save significant amounts of disk space without any additional work.
There are still many other features, such as subvolumes, subvolume quotas, data deduplication, snapshots, and others. All of these make it an excellent filesystem choice.
My Experience
My initial setup went fairly well, and has been working perfectly since. I have subvolumes to separate working data from backups and enabled transparent compression to save some disk space. Unfortunately, data deduplication requires more RAM to successfully manage than I have available.
My one complaint so far is that determining free disk space is difficult. Unlike ext4, I can’t just run df -h /dev/sda and get a percent full.
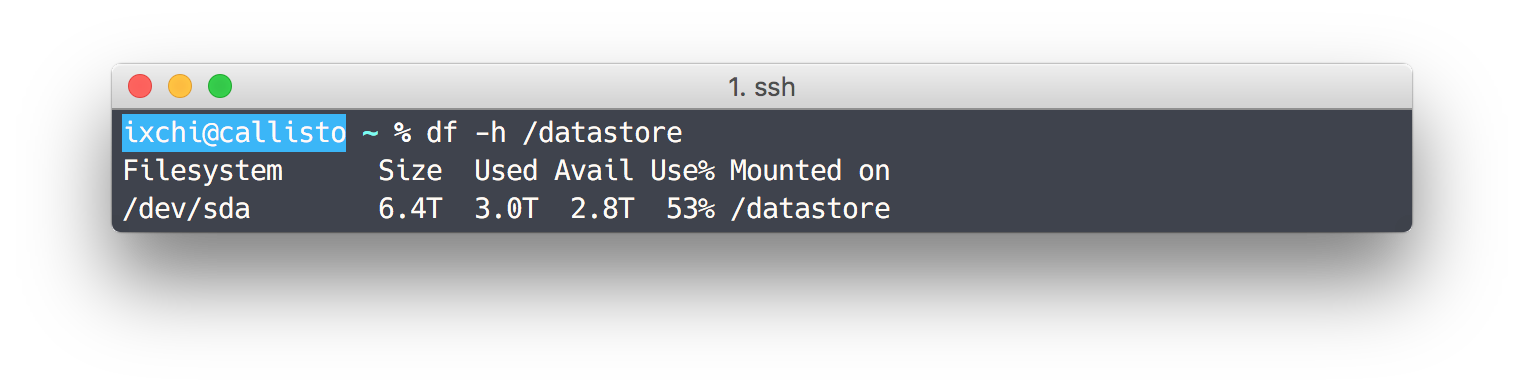
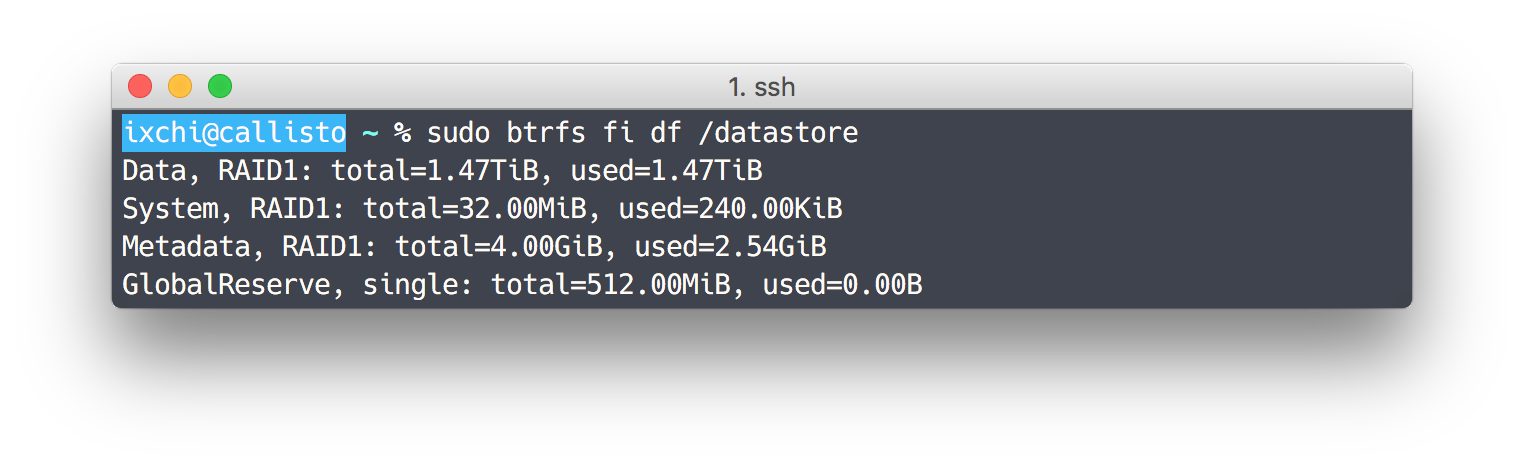
Running df reports that I have used 3.0TiB of data and have 2.8TiB free. Running Btrfs’ own df-like tool reports that I have only used 1.47TiB of data. A rough estimate suggests that I have less than 1.4TiB free.
Conclusion
As Btrfs is a newer filesystem, some data recovery tools may not work well with it. It also isn’t supported on all platforms yet. While the developers claim it is stable, it has not gone through the same time trials as other filesystems have.
Companies such as Facebook and Jolla among various others have adopted Btrfs for use in their production environments. Some NAS devices have Btrfs support, if you wish to enable it.
With my current experience, I would recommend using Btrfs if you have proper backups of all your data and wish to make sure your data is always available and always correct. While I don’t expect to encounter any issues with data integrity, being prepared is always better than the alternative.
If you wish to look into it more or learn how to use, the Btrfs Wiki is an excellent source of updated and accurate information.